TurtleBot3使用课程-第四节(北京智能佳)
1.机器学习
1.1 机器学习一:object_detector_3d
1.1.1目标
使用链式机(机器学习框架之一)识别一个对象,并使用深度相机计算到对象的距离。(Link : chainer)
1.1.2操作环境

1.1.3设置
1.ROS动能装置:参考wiki.ros.org
2.RealSense D435 ROS包安装
![]()
3.依赖包装安装python-pip包
4.object_detector_3D安装
1.1.4运行(它需要超过几秒取决于PC)
1.Realsense&object_detector_3d节点
![]()
2.Rviz
![]()
1.1.5运行屏幕
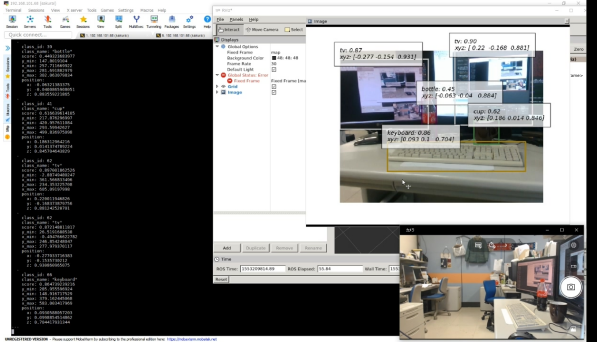
左到图:显示由rostopicecho/object_detection_3d输出。
图的右上角:/object_detection_3d/result_image通过rviz显示。
如果你看右上屏幕,你可以看到一个键盘,一个杯子,一个瓶子和两个显示器从前面检测到。 每个检测都有一个标题,显示以下信息。
对象名称
检测得分。值在[0,1]范围内,随着值接近1,检测的可靠性增加。
对象中心点的三维坐标(稍后介绍)。的起源坐标系是相机的中心。x、y和z轴方向是以米为单位,分别指向右、下和向内。
如果你看z值,它是在深度方向上五个元素之间的距离检测结果,可以看到值随着对象的位置而增加再往里走。
1.1.6 ROS节点
1.主题
订阅主题
相机/颜色/image_raw[sensor_msgs/图像]彩色图像,用于二维物体检测
/相机/深度/颜色/点[sensor_msgs/点云2]
3D点云,用于计算3D坐标,需要与上面的相机图像进行时间同步
出版的主题
/object_detection_3d[object_detector_3d/第3条]

本主题由检测对象(num_detections)和检测信息(检测)的数量组成)。 检测信息Detection3D由以下信息组成。
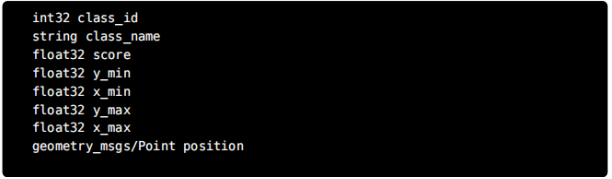
class_id和class_name是检测对象的分类编号和名称。 得分意味着检测的可靠性。 y_min、x_min、y_max和x_max是被检测对象的包围框的左上角和右下角的坐标。 最后,位置是物体的三维坐标位置。
△ object_detection_3d/result_image[sensor_msgs/图像]
这是一个结果图像,其中包括用于检测的图像中检测到的对象的信息。 这是一个像上面右边的图像。
其他
△ sensor_msgs的内部参数。 相机信息:/相机/颜色/image_raw
△ realsense2_camera。 外部参数:从点组坐标系转换为彩色摄像机坐标系的外部参数。
1.1.7 ROS节点
1.输入数据
输入
二维摄像机图像
三维云
摄像机内部参数
外部参数,指示摄影机在点云中的位置坐标系。
输出
对象在点云坐标系中的中心点坐标。
对象的类型
检测的可靠性
2.算法概述
1.按照下面的步骤提取对象的3D坐标。
2.使用对象检测器检测图像中的多个对象,并从摄像机获得的图像中输入。
3.提取视图截锥中包含的每个点对应的子集。
4.找到每个点子集组的中心点坐标。
5.将二维检测结果和三维中心点坐标集成到三维中检测结果。
3.每种算法的描述
2D对象检测2D对象检测是指预先定义好的检测包含在图像中的对象。当您输入二维图像进行搜索时显示以下信息。以下是多个对象对应的预测值。
对象周围的框(轴对齐边界框,bbox)
对象的类型
检测可靠性
具体地说,目标探测器使用COCO和can学习的SSD300利用CNN检测80种物体。有关详细的检测列表,请参阅该列表显示在链接中。python的深度学习框架chainer用于实现和chainerv专门用于图像处理。
提取检测对象的点子集时,使用bbox上一步骤中的信息。对于每个bbox,仅限进入bbox的点从摄像机的视角提取点云中的点云作为部分点云。
部分点云中的中心点计算部分点云包括从目标、背景和屏蔽对象获得的点。这个表示这些点的集中点称为中心点。虽然对中心点有不同的定义,但中心点是从软件角度定义为点云的中心。然而,这种方法使用点数据而不区分提取的对象和非对象部分。这可能会导致根据对象形状或差异bbox。将中心点定义为计算中心似乎更好在从部分点云中移除未提取的部分后。
二维检测与三维中心点坐标的集成省略,因为它很简单。
1.2 机器学习二:YOLO
1.2.1 目标
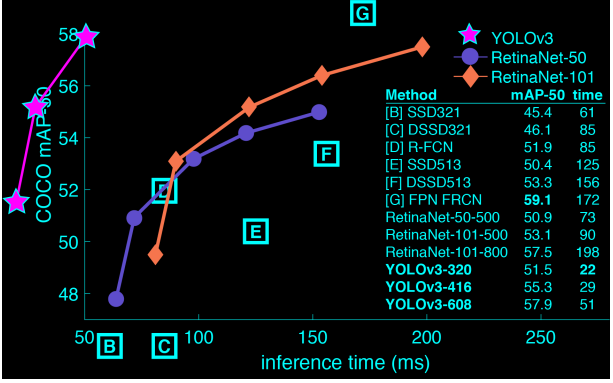
使用YOLO练习在ROS环境中识别对象。 YOLO(您只看一次)是一个实时的目标检测系统,比其他检测系统具有更快的速度。 YOLO由darknet提供动力,darknet是一种神经网络框架,它教育和运行DNN(深度神经网络)。
1.2.2 操作环境

1.2.3 设置
ROS动能装置:参考。wiki.ros.org
RealSense D435 ROS包安装
![]()
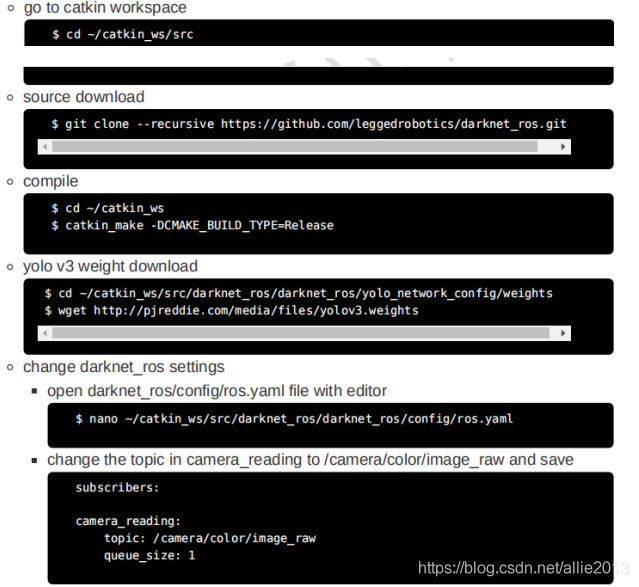
darknet_ros安装转到catkin工作区
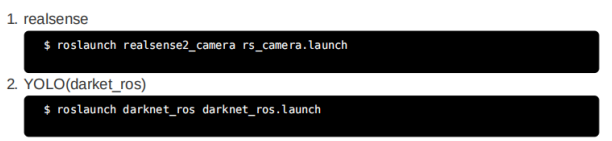
1.2.4运行(使用预先训练的模型)
1.2.5运行屏幕
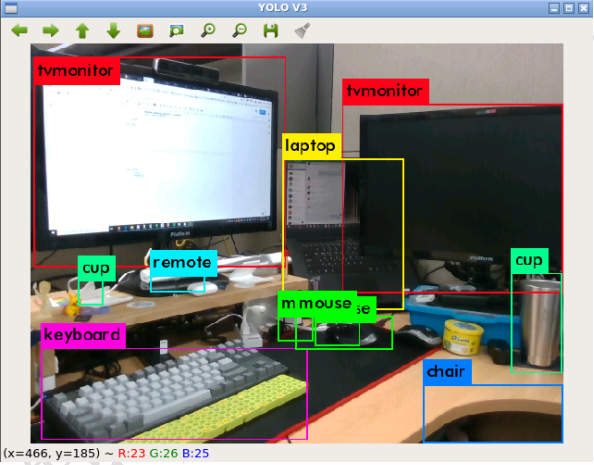
与上面的图像一样,多个对象同时被识别。 在对象的边界创建一个框,对象的名称显示在框的左上方。
1.2.6 ROS节点
1.主题
订阅的主题
/照相机/颜色/图像_raw[传感器图像/图像]彩色图像,用于目标检测外部参数,指示摄影机在点云中的位置坐标系。
已发布主题
/暗色/边框本主题包含已识别对象的信息。如下图所示由消息头、用于检测的图像头组成,边界盒是检测到的目标信息。

显示对象信息的边界框如下所示。(BoundingBox.msg)

它由表示探测精度的概率x和y组成检测对象图像上边界框的坐标,id号以及指示对象类型的类。/暗色/探测图像[传感器图像]包含图像中检测到的对象信息的结果图像用于检测。/暗色/找到目标[标准消息/国际标准]显示检测到的对象数。
2.行动
摄像头读数[传感器图像]发送包含图像和结果值的操作(的边界框检测到的对象)。
3.参数
设置与检测相关的参数可以在与 ![]() ROS相关参数设置可以在中完成
ROS相关参数设置可以在中完成 ![]()
图像查看/启用打开CV(bool)打开/关闭打开cv查看器,其中显示包含边界框。图像查看/等待按键延迟(int)打开cv查看器中的等待键延迟(毫秒)yolo_model/config_file/name(字符串)用于检测的网络的cgf名称。加载具有相应名称的cfg从darknet_ros/yolo_network_config/cfg中使用该程序。yolo_型号/重量_文件/名称(字符串)用于检测的网络的权重文件名。加载权重文件来自darknet_ros/yolo_network_config/weights的相应名称以使用程序。yolo_型号/阈值/值(浮动)检测算法的阈值。范围在0到1之间。yolo_模型/检测_类/名称(字符串数组)网络可检测到的对象的名称。
1.2.7 GPU Acceleration
如果你有NVdia GPU,使用CUDA可以比只使用快几倍中央处理器。如果安装了CUDA,则会在中自动识别CMakeLists.txt文件文件和编译时以GPU模式编译(catkin_make)
CUDA Toolkit
1.2.8 参考站点
darknet
darknet_ros
下一篇 >>